Baseline
Challenge entrants are supplied with a fully functioning baseline system.
Figure 2 shows a detailed schematic of the baseline system:
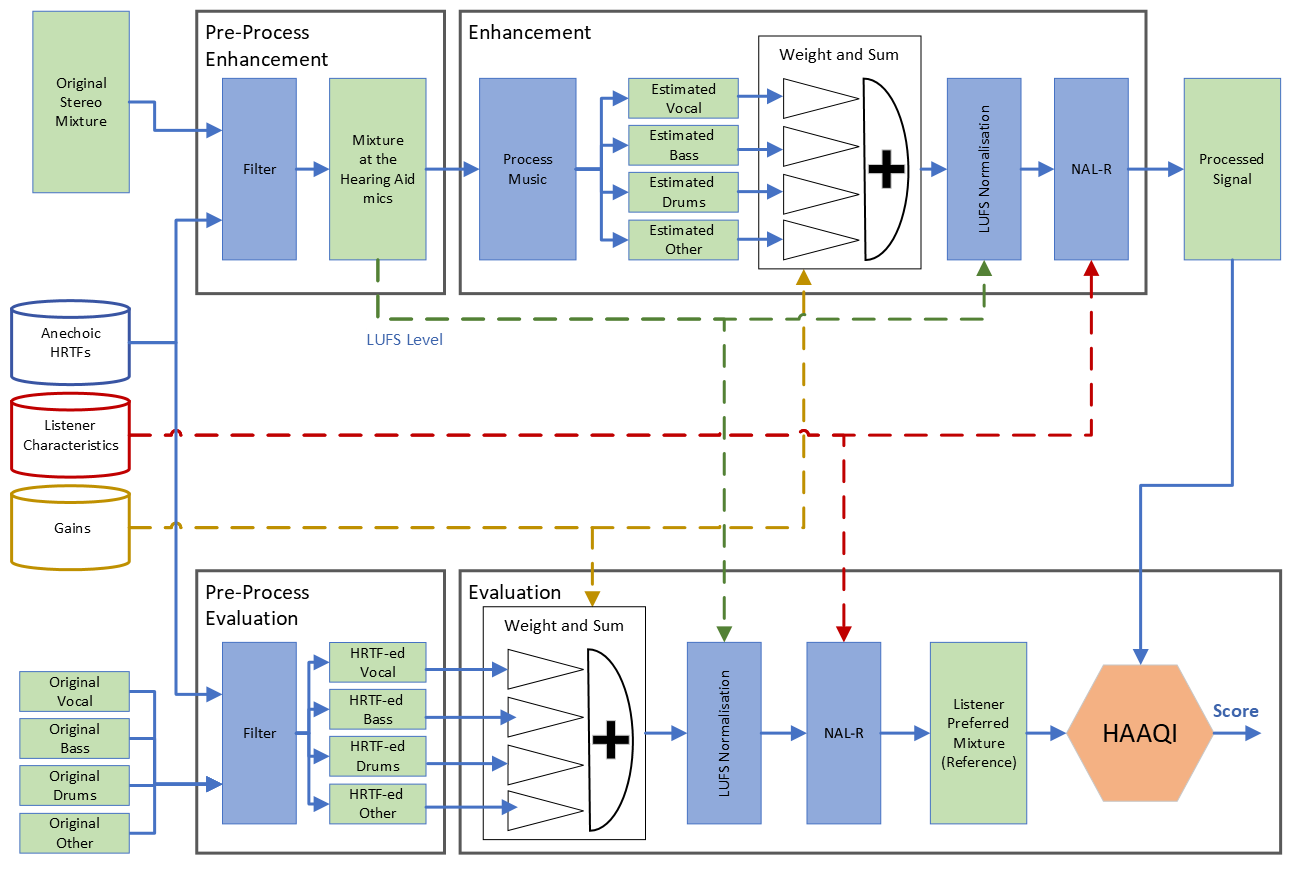
where:
- Green boxes represent audio signals.
- Blue boxes represent operations applied to the audio signals.
- Blue database box is the anechoic HRTF dataset (audio signals).
- Red database box is the listener characteristics dataset (metadata information).
- Yellow database box is the gains dataset (metadata information).
- White 'Weight and sum' box is the downmix operation.
- Solid lines are signals transferred from one state of process to the next.
- Dashed lines are metadata information.
The Pre-Process blocks
The system starts by applying HRTFs to the music of MUSDB18-HQ dataset, simulating the music as it is picked up by the hearing aids microphones.
This stage is illustrated by the "pre-process enhancement" and "pre-process evaluation" boxes. However, in practice both boxes
correspond to the output of the generate_at_mic_musdb18.py script.
- First, it takes the
Scenedetails:- MUSDB18-HQ music (mixture, vocal, drums, bass, other).
- Subject head and loudspeaker-position (HRTFs).
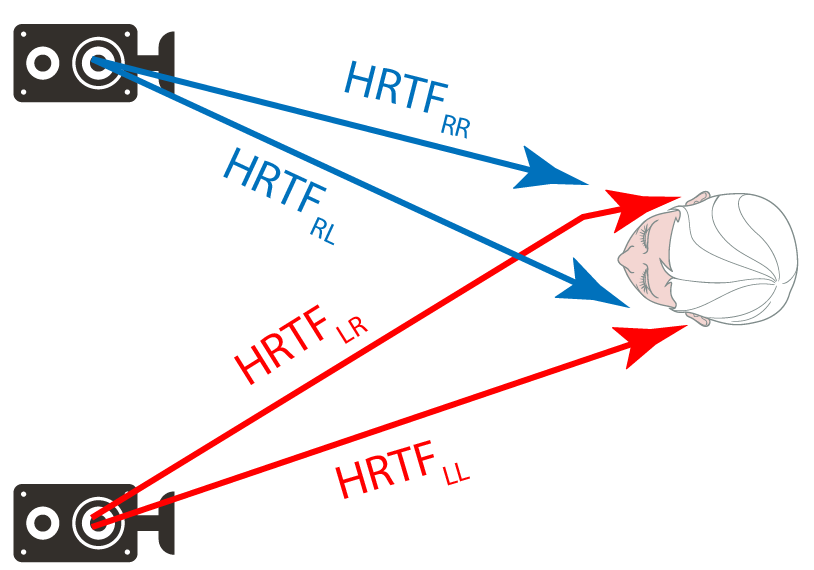
- It applies the HRTFs to the left and right side of all signals (mixture and VDBO components) [Figure 2]
- The mixture with HRTF applied corresponds to the output of the "pre-process enhancement" block.
- The VDBO signals with HRTF applied correspond to the output of the "pre-process evaluation" block.
The Enhancement block
The enhancement takes a mixture signal as it is picked up by the hearing aids microphones and attempts to output a personalized rebalanced stereo rendition of the music.
- First, it takes stereo tracks ("mixture at the hearing aid mics") and demixes them into their VDBO (vocal, drums, bass and other) representation. This is done by using an out-of-the-box audio source separation system.
- Then, using the gains provided, the music is downmixed to stereo after changing the level of the different elements of the music.
- Next, the downmixed signal is normalised to match the LUFS level of the input mixture.
- NAL-R amplification is applied to the normalised downmixed signal, allowing for a personalised amplification for the listener using a standard hearing aid algorithm.
- This amplified signal is the output of the system:
Processed signal
The Evaluation block
The evaluation generates the reference and processed signals and computes the HAAQI score.
- First, it takes the VDBO signals at the hearing aid microphones (these are the VDBO components provided by MUSDB18-HQ with the HRTF applied to them) and remixes the signals using the same gains as applied in the enhancement.
- Then, it normalises the remix to the same LUFS level as the "mixture at the hearing aid mics".
- Next, it applies the NAL-R amplification.
- This process results in the
Reference signalfor HAAQI, which simulates a "listener preferred mixture". The reference signal corresponds to an ideal rebalanced signal when we have access to the clean VDBO components. - As HAAQI is an intrusive metric, the score is computed by comparing the
Processed signal(downmixed music) with theReference signal, focussing on changes to time-frequency envelope modulation, temporal fine structure and long-term spectrum.
- In the Enhancement and Evaluation blocks, we apply a loudness normalisation (in LUFS) after applying the gains. This is to keep the loudness of the remix at the same levels as the mixture at the hearing aid mics.
- As required by HAAQI, we resample both the reference and processed signal before computing the score.
Baseline Scores
Two baseline systems are proposed by employing two out-of-the-box audio source separation systems in the enhancement block.
The average HAAQI scores are:
| System | Left HAAQI | Right HAAQI | Overall |
|---|---|---|---|
| Demucs | 0.6690 | 0.6665 | 0.6677 |
| OpenUnmix | 0.5986 | 0.5940 | 0.5963 |
References
[1] Kates, J.M. and Arehart, K.H., 2016. The Hearing-Aid Audio Quality Index (HAAQI), in IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 24, no. 2, pp. 354-365, doi: 10.1109/TASLP.2015.2507858
[2] Défossez, A. "Hybrid Spectrogram and Waveform Source Separation". Proceedings of the ISMIR 2021 Workshop on Music Source Separation. doi:10.48550/arXiv.2111.03600
[3] Stöter, F. R., Liutkus, A., Ito, N., Nakashika, T., Ono, N., & Mitsufuji, Y. (2019). "Open-Unmix: A Reference Implementation for Music Source Separation". Journal of Open Source Software, 4(41), 1667. doi:10.21105/joss.01667