Objective measures for hearing-aid audio
HASPI and HASQI
Below is a by James Kates on two objective measures used for evaluating the intelligibility and quality of hearing-aid processed speech. These metrics have much in common with the metric we're using in the first challenges for music, HAAQI [1].
Click here for synopsis
Signal degradations, such as additive noise and nonlinear distortion, can reduce the intelligibility and quality of a speech signal. Predicting intelligibility and quality for hearing aids is especially difficult since these devices may contain intentional nonlinear distortion designed to make speech more audible to a hearing-impaired listener. This speech processing often takes the form of time-varying multichannel gain adjustments. Intelligibility and quality metrics used for hearing aids and hearing-impaired listeners must therefore consider the trade-offs between audibility and distortion introduced by hearing-aid speech envelope modifications. This presentation uses the Hearing Aid Speech Perception Index (HASPI) and the Hearing Aid Speech Quality Index (HASQI) to predict intelligibility and quality, respectively. These indices incorporate a model of the auditory periphery that can be adjusted to reflect hearing loss. They have been trained on intelligibility scores and quality ratings from both normal-hearing and hearing-impaired listeners for a wide variety of signal and processing conditions. The basics of the metrics are explained, and the metrics are then used to analyze the effects of additive noise on speech, to evaluate noise suppression algorithms, and to measure differences among commercial hearing aids.
HAAQI (Hearing Aid Audio Quality Index)
HAAQI was developed by James Kates and Kathryn Arehart and is an intrusive (double-ended) metric, i.e., it requires both a processed and reference signal [1]. In the Cadenza evaluation, the HAAQI function is configured so the reference signal has a amplification applied, so all frequency bands contribute equally to its loudness. This amplification uses the NAL-R prescriptive (gain) formula [2]. This prescribes the amount of gain across frequency bands to apply to the incoming signal based on the individual pure-tone audiogram thresholds at those frequencies (in dB HL) to improve audibility. This is linear amplification and no compression.
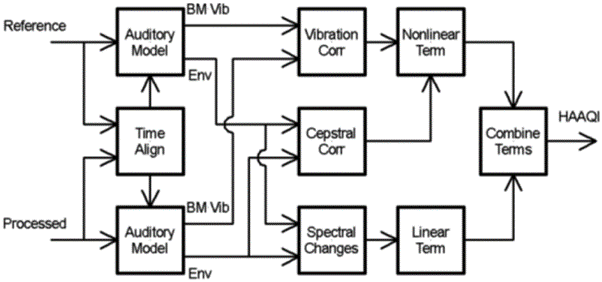
A schematic for the rest of HAAQI is shown Figure 1. HAAQI involves an auditory model including hearing thresholds to allow for hearing loss via the audiogram and gain. HAAQI then compares the temporal fine-structure (BM Vib in Fig. 1) and the envelope of the two signals (Env) using correlation (Corr) and quantifying spectal differences. (The processes are similar to HASQI; see video above). The main difference to HASQI is the way the separate linear and non-linear terms are combined to predict perceived quality ("combine terms"). The metric has been shown to predict well the effects of additive noise (e.g., background noise and/or artefacts) as well as noise reduction, nonlinearities (e.g., compression) and spectral shifts. But it has not been used before to explore demixed signals, as is being done in Task 1 of the 2023 challenge.
User's Guide
For more information about the design and use of HASPI, HASQI and HAAQI, please refer to the official user's guide.
In the HAAQI Python implementation, the parameter equalisation indicates if the reference signal already includes
an amplification or not. If the reference signal does not include an amplification, one have to set the parameter
equalisation = 1. This will make to HAAQI to apply the NAL-R amplification.
It is important to note that the processed signal must include the hearing aid amplification before is presented to HAAQI.
No hearing aid amplification is applied to this signal within the HAAQI score.
Reference
[1] Kates, J.M. and Arehart, K.H., 2015. The hearing-aid audio quality index (HAAQI). IEEE/ACM transactions on audio, speech, and language processing, 24, pp.354-365.
[2] Byrne, D. and Dillon, H., 1986. The National Acoustic Laboratories'(NAL) new procedure for selecting the gain and frequency response of a hearing aid. Ear and hearing, 7(4), pp.257-265.