Word Correctness#
In summary, the correctness of a signal is computed as:
\(
\text{Correctness} = \frac{\sum{\text{Correct words}}}{\sum{\text{Total words}}}
\)
To compute this score, we employ the Whisper [RKX+23] model. Whisper is a robust speech recognition system trained in a very large dataset under different acoustic conditions.
Despite Whisper being trained for speech recognition, the large variable acoustic conditions makes it capable of transcribing lyrics.
The correlation of Whisper model base.en with human performance (Ibrahim data) is 0.69.
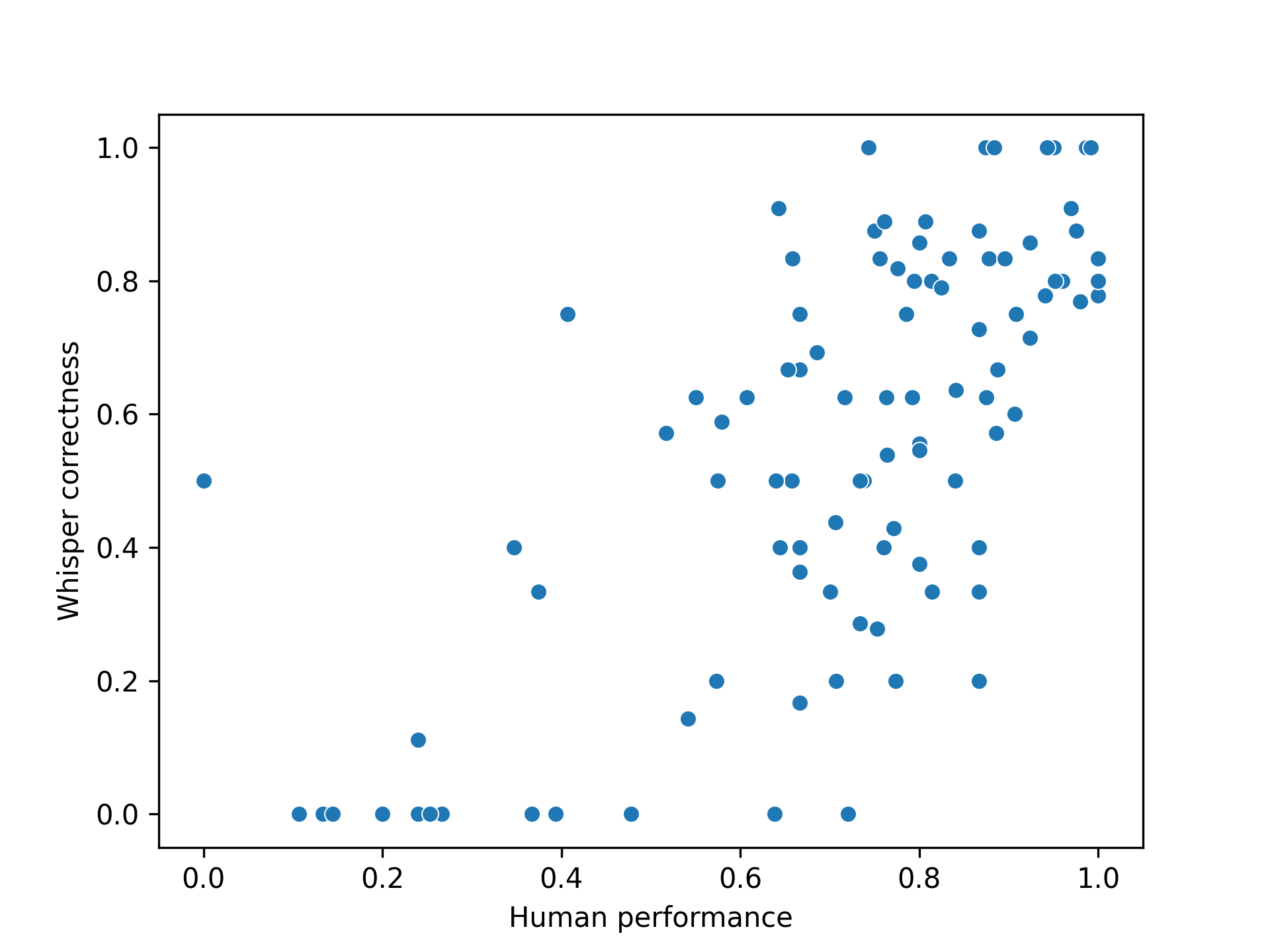
In this case, the transcription was run on the original mixture, that is, without supressing the background accompaniment.
Google Colab
To run this tutorial on Google Colab, you will need install the PyClarity module by uncommenting and running the next cell.
# print("Cloning git repo...")
# !git clone --depth 1 --branch v0.6.1 https://github.com/claritychallenge/clarity.git
# print("Installing the pyClarity...\n")
# %cd clarity
# %pip install -e .
# clear_output()
# print("Repository installed")
Computing Correctness in Cadenza.#
To automatically compute the intelligibility for a hearing loss listener, we need to simulate how someone with a hearing loss is hearing such signals. For this the signal to evaluate needs:
Apply amplification according to the hearing loss thresholds (audiograms). E.g. using multiband dynamic range compressor.
Simulate hearing loss. E.g. using the MSGB hearing loss simulation.
One can argue that the intelligibility depends on how the words are understood by the better ear and not an average between left and right ear. Therefore in Cadenza, we compute the intelligibility as the maximun correctness between the left and right channels.
Let’s run an example:
Let’s take a 6-second excerpt from Aretha Franklin’s As Long As You There. The lyrics of this sample are
... as long as you hold my hand ...
!wget "https://github.com/CadenzaProject/cadenza_tutorials/raw/main/_static/audio/Aretha%20Franklin-As%20Long%20As%20You%20There.wav"
--2024-09-13 14:47:03-- https://github.com/CadenzaProject/cadenza_tutorials/raw/main/_static/audio/Aretha%20Franklin-As%20Long%20As%20You%20There.wav
Resolving github.com (github.com)... 20.26.156.215
Connecting to github.com (github.com)|20.26.156.215|:443... connected.
HTTP request sent, awaiting response... 302 Found
Location: https://raw.githubusercontent.com/CadenzaProject/cadenza_tutorials/main/_static/audio/Aretha%20Franklin-As%20Long%20As%20You%20There.wav [following]
--2024-09-13 14:47:03-- https://raw.githubusercontent.com/CadenzaProject/cadenza_tutorials/main/_static/audio/Aretha%20Franklin-As%20Long%20As%20You%20There.wav
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.109.133, 185.199.111.133, 185.199.110.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.109.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1058448 (1.0M) [audio/wav]
Saving to: ‘Aretha Franklin-As Long As You There.wav’
Aretha Franklin-As 100%[===================>] 1.01M --.-KB/s in 0.09s
2024-09-13 14:47:03 (11.5 MB/s) - ‘Aretha Franklin-As Long As You There.wav’ saved [1058448/1058448]
import IPython.display as ipd
from scipy.io import wavfile
reference = "as long as you hold my hand"
sr, signal = wavfile.read(
"Aretha Franklin-As Long As You There.wav"
)
ipd.display(ipd.Audio(signal.T, rate=sr))
Let’s run Whisper on this excerpt:
import whisper
whisper_model = whisper.load_model('base.en')
hypothesis = whisper_model.transcribe("Aretha Franklin-As Long As You There.wav", fp16=False)['text']
hypothesis
' And long as you hold my hand'
from jiwer import compute_measures
results = compute_measures(reference, hypothesis)
results
{'wer': 0.14285714285714285,
'mer': 0.14285714285714285,
'wil': 0.26530612244897966,
'wip': 0.7346938775510203,
'hits': 6,
'substitutions': 1,
'deletions': 0,
'insertions': 0,
'ops': [[AlignmentChunk(type='substitute', ref_start_idx=0, ref_end_idx=1, hyp_start_idx=0, hyp_end_idx=1),
AlignmentChunk(type='equal', ref_start_idx=1, ref_end_idx=7, hyp_start_idx=1, hyp_end_idx=7)]],
'truth': [['as', 'long', 'as', 'you', 'hold', 'my', 'hand']],
'hypothesis': [['And', 'long', 'as', 'you', 'hold', 'my', 'hand']]}
Computing the correctness:
Now, to run the same system for hearing loss conditions, we first need to amplify the signal. For that, we will employ the multiband dynamic range compressor. Then, we will use MSGB to simulate how the amplified signal is picked up by a person with hearing loss.
Amplification#
In the CAD2 baseline, the amplification stage is part of the enhancer stage in the enhancer.py script. This is the signal to submit.
from clarity.enhancer.multiband_compressor import MultibandCompressor
import numpy as np
# Audiograms for left and right side
HL_left = np.array([20, 20, 30, 40, 50, 60])
HL_right = np.array([40, 50, 60, 40, 30, 60])
# Left side
mbc = MultibandCompressor(
crossover_frequencies=(
np.array([250, 500, 1000, 2000, 4000]) * np.sqrt(2)
),
sample_rate=sr,
compressors_params={
"attack": [11, 11, 14, 13, 11, 11],
"release": [80, 80, 80, 80, 100, 100],
"threshold": -40,
"ratio": 4,
"makeup_gain": np.maximum((HL_left - 20) / 3, 0),
"knee_width": 0,
}
)
compressed_signal_left = mbc(signal[:, 0], return_bands=False)[0]
# Right side
mbc = MultibandCompressor(
crossover_frequencies=(
np.array([250, 500, 1000, 2000, 4000]) * np.sqrt(2)
),
sample_rate=sr,
compressors_params={
"attack": [11, 11, 14, 13, 11, 11],
"release": [80, 80, 80, 80, 100, 100],
"threshold": -40,
"ratio": 4,
"makeup_gain": np.maximum((HL_right - 20) / 3, 0),
"knee_width": 0,
}
)
compressed_signal_right = mbc(signal[:, 1], return_bands=False)[0]
Now, to run the evaluation we need to apply the hearing loss simulator to each side using the same audiograms.
The next code corresponds to steps run by the evaluation.py script. The evalyuation takes the amplified signal (generated by the enhancer) and applies the hearing loss simulation before computing the correctness.
from clarity.evaluator.msbg.msbg import Ear
from clarity.utils.audiogram import Audiogram
audiogram_left = Audiogram(
levels=HL_left,
frequencies=[250, 500, 1000, 2000, 4000, 8000]
)
audiogram_right = Audiogram(
levels=HL_right,
frequencies=[250, 500, 1000, 2000, 4000, 8000]
)
ear = Ear(
equiv_0db_spl=100,
sample_rate=sr,
)
# Left side
ear.set_audiogram(audiogram_left)
enhanced_left = ear.process(compressed_signal_left)[0]
# Right side
ear.set_audiogram(audiogram_right)
enhanced_right = ear.process(compressed_signal_right)[0]
Now, let’s save the left and right channels in independent files:
wavfile.write(
"left_side.wav",
sr,
enhanced_left,
)
wavfile.write(
"right_side.wav",
sr,
enhanced_right,
)
Compute Correctness for each side and select the maximum using the same model as before
whisper_model = whisper.load_model('base.en')
hypothesis_left = whisper_model.transcribe("left_side.wav", fp16=False)['text']
hypothesis_left
' As long as you hold my hand'
hypothesis_right = whisper_model.transcribe("right_side.wav", fp16=False)['text']
hypothesis_right
" As long as you're home my head"
results = compute_measures(reference, hypothesis_left)
score_left = results['hits'] / (results['hits'] + results['substitutions'] + results['deletions'])
results = compute_measures(reference, hypothesis_right)
score_right = results['hits'] / (results['hits'] + results['substitutions'] + results['deletions'])
print(f"Left: {score_left:0.2f}, Right: {score_right:0.2f}")
Left: 0.86, Right: 0.43
correctness = max(score_left, score_right)
correctness
0.8571428571428571