Baseline
Challenge entrants have a fully functioning baseline system to build from.
1. Task 1: Headphones
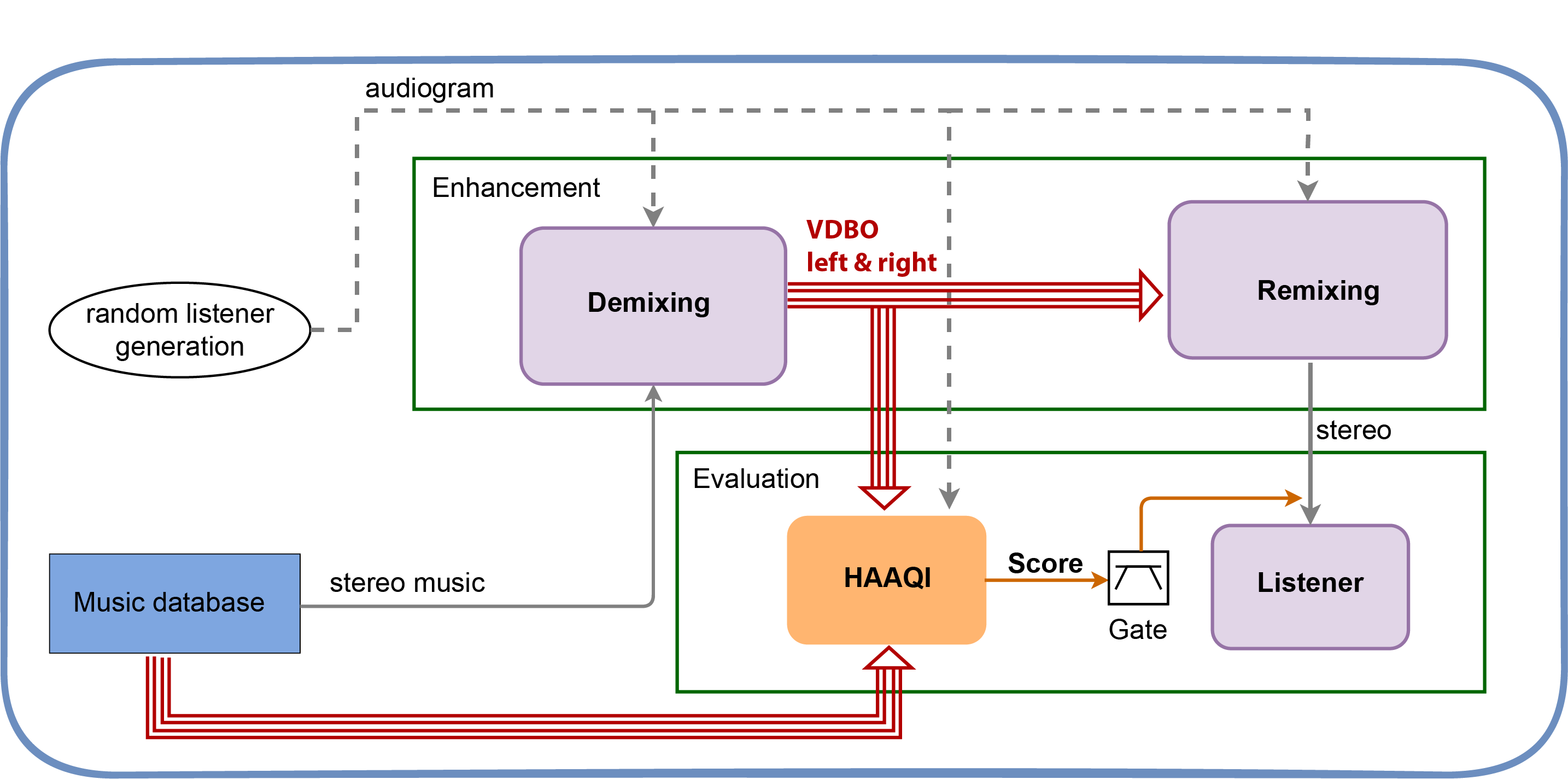
The music databases (blue box) are available in object based format, allowing us to create both stereo input to the demixer (grey line) and music in VDBO (vocal, drums, bass, other) format (red lines). These later signals form the reference VDBO signals that are needed for the objective evaluation using HAAQI (Hearing Aid Audio Quality Index) [1]. The demixing part is therefore a variant on a standard demixing challenge, except the quality of the separation is evaluated using HAAQI rather than a measure like SDR (Signal to Distortion Ratio).
The audiogram metadata allows the music enhancement (e.g. demixing/remixing) to be individualised to the hearing ability of the listener (dash grey lines).
The VDBO signals are remixed to give the stereo output from the headphones. It would be possible to use a simple remixer that uses the levels stated in the original music's metadata. But there is freedom here to experiment with changing the remixing to improve the audio quality for the listeners.
1.1 Baseline system
We are presenting two baseline systems using two out-of-the-box systems trained exclusively on the MUSDB18 training data.
- The time-domain system Hybrid Demucs music source separation model. This model is publicly available in the TorchAudio library.
- The spectrogram-based system Open-Unmix model. This model is publicly available through
torch.hub.
The output of the demixing is 8 stems corresponding to the left and right channel for each source, i.e., left vocal, right vocal, left bass, right bass, and so on.
Then, a NAL-R amplification and compression is applied to each stem using the personalized audiogram of each listener. NAL-R is a prescription formulation for fitting simple hearing aids. This then creates the output stems.
These output stems are then evaluated by computing the mean HAAQI score of each stem.
For the remixing procedure, the baseline simply does a linear addition of the output stems.
Your challenge is to improve the demixing and remixing blocks in the "enhancement" box. The rest of the baseline is fixed and should not be changed.
2. Task 2: Car
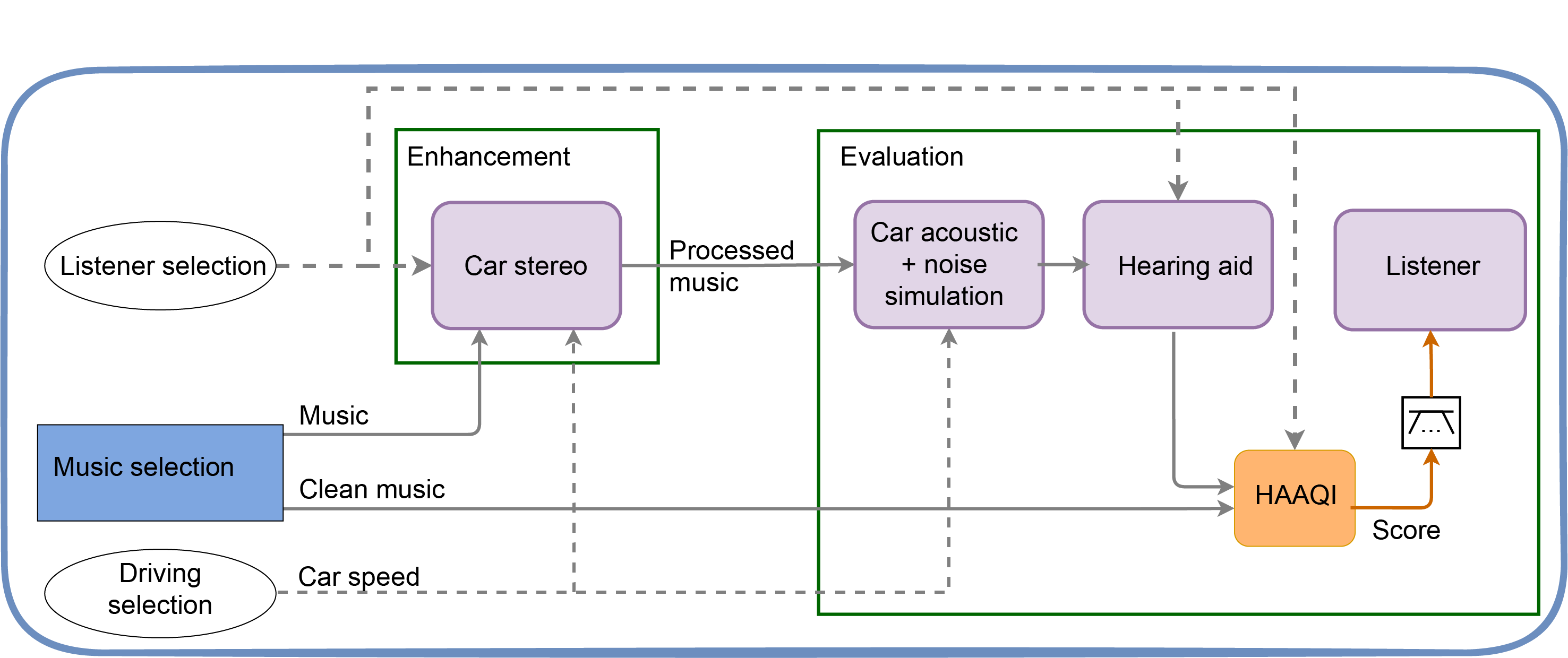
The music database (blue box) provide samples as input to the car stereo and also reference left and right stereo signals for evaluating using HAAQI. Your task is to process the music taking into account the listener audiogram and also the car noise. You have access to the car metadata (e.g. speed), which will determine the power spectrum of the car noise.
The evaluation starts by predicting the signals at the microphones of the hearing aids. The effect of the 'room' acoustics is simulated by applying Binaural Room Impulse Responses (taken from the eBrIRD database). The car noise comes from a simulator we provide.
After the car noise and acoustic simulation, the signals are then processed by a simple hearing aid. This then provides left and right signals that can be used for evaluation either by HAAQI or the listening panel.
Your challenge is to improve the car stereo ('Enhancement'). The 'Evaluation' is fixed and should not be changed.
2.1 Baseline system
In enhancement, the baseline system simply normalises the signal accordingly to the average audiogram of the ear with greater hearing loss. The system attenuates the signal and saves it at 16 bit resolution.
In the evaluation stage, the car noise and car acoustics characteristics (HRTFs) are added to the enhanced signal. This signal is then passed to a simple hearing aid (HA) composed of a NAL-R amplification.
The output of the HA is use for HAAQI and listening panel evaluation.
An important issue to be aware of is the possibility of the hearing aid producing signals with an amplitude that causes clipping. When this happens, the system prints warning messages in the log file, including the track path and the number of clipped samples.
More details can be found in the core software page.
2.1.1 Loudness consideration in enhancement
The baseline enhancement system simply sets an appropriate level for the original music based on the music and audiogram of the listener. It isn't perfect and some samples still clip!
- Computes the level in dB LUFS (loudness units relative to full scale) of the original song, i.e., the song from the dataset.
- Computes the average hearing loss (HL) for each ear. Refer to measuring hearing impairment resource to understand how this average is computed.
- Set a temporal target level according maximum average HL.
- If average is equal or greater than 50, set the temporal target level to -19 dB LUFS. Then, for every 5dB LUFS over 50 dB, reduce the level in an additional 1 dB LUFS.
- Otherwise, set the temporal target level at -14 dB LUFS.
- The final target level for normalisation is set as the minimum between the temporal target and the original song levels.
Example: All levels are in dB LUFS
| Song | Max average HL | Original Level | Temp Target Level | Final Level |
|---|---|---|---|---|
| 1 | 35 | -13 | -14 | -14 |
| 2 | 42 | -15 | -14 | -15 |
| 3 | 50 | -15 | -19 | -19 |
| 4 | 60 | -13 | -19 | -21 |
The levels of -14 and -19 dB LUFS were set according to Spotify standard.
2.1.1 Loudness consideration in evaluation
For the signal passing through the hearing aid. The enhanced signal ("processed music in above diagram") has the car acoustic characteristics and car noise added (See here). This then goes into the hearing aid, which is a simple linear amplifier. If any sample values exceed +1 (or are below -1) on the output of the hearing aid, they are then set to +1 (or -1). Consequently, setting the levels of the enhancement signals to prevent clipping at this point is vital.
For the reference signal ("clean music") passing to HAAQI, a simple stereo set up in a dead room is simulated:
- Anechoic HRTFs are applied to the reference signal to simulate the stereo set-up. This then gives the music at the listener ear canal.
- The reference signal is then normalise to the lower loudness between the enhanced signal after adding the car acoustics and -14 dB LUFS. This becomes the reference signal for HAAQI evaluation.
3. References
[1] Kates, J.M. and Arehart, K.H., 2016. The Hearing-Aid Audio Quality Index (HAAQI), in IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 24, no. 2, pp. 354-365, doi: 10.1109/TASLP.2015.2507858.