Summary Task 1
1. Description of the Problem
A person with a hearing loss is listening to music via headphones. They're not using their hearing aids.
The machine learning task is to decompose a stereo song into a VDBO (vocal, drums, bass and other) representation. This then allows a personalised remixing for the listener that has better audio quality. For example, for some music you might amplify the vocals to improve the audibility of the lyrics.
As shown in Figure [1], the system is split into two stages; the enhancement and evaluation.
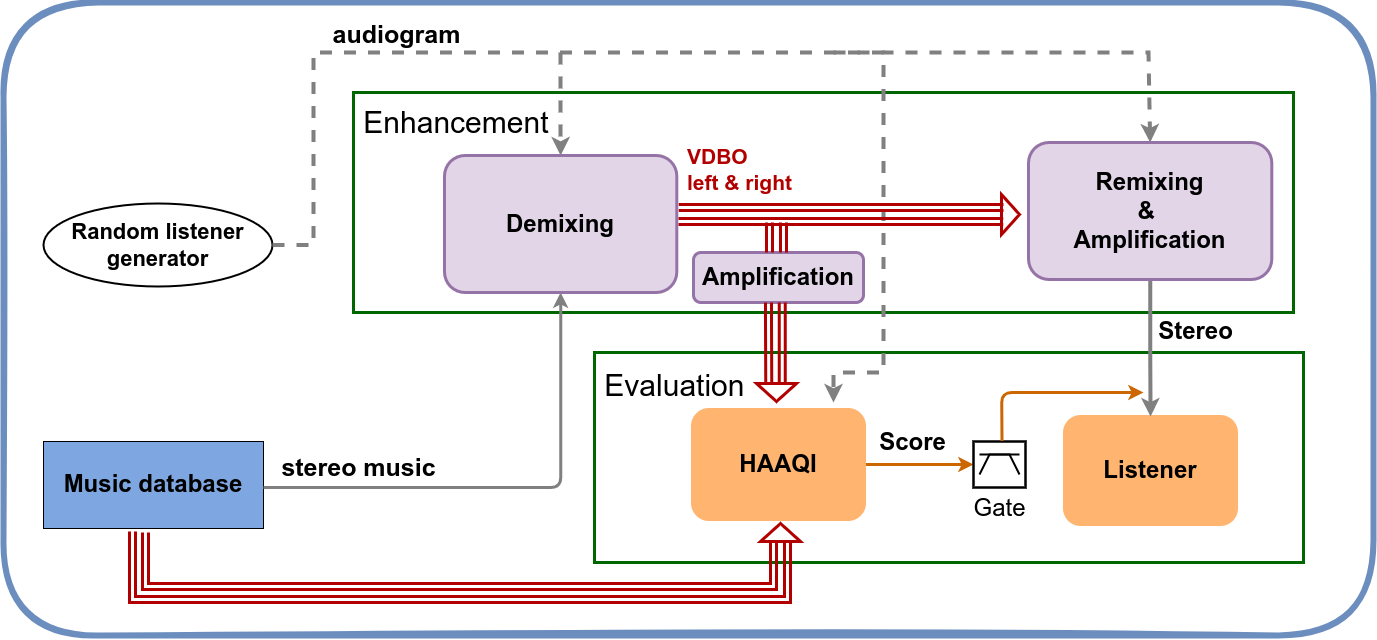
1.1 Enhancement Stage
You can adapt and modify the baseline enhancement script or make your own script.
Your task is to decompose a stereo music signal and produce 8 mono signals or stems corresponding to the
right and left vocal, drums, bass and other (VDBO), and produce one stereo signal corresponding to a
remix signal optimised for a target listener.
For this, you will have access to relevant datasets that will allow you to explore different approaches to separate the music and/or to remix the signals.
1.1.1 Dataset
In the enhancement stage, you have access to:
- Full length songs from MUSDB18-HQ dataset.
- Music data for augmentation, if needed.
- Listeners characteristics (audiograms). Listener Data
Please refer to task 1 data page and the baseline readme for details.
To download the datasets, please visit download data and software.
1.1.2 Output
The output of this stage are:
- Eight stems corresponding to the left and right vocal, bass, drums and other stems.
- Sample rate = 24000 Hz
- Precision: 16bit integer
- Compressed using FLAC
- One stereo remixed signal
- Sample rate = 32000 Hz
- Precision: 16bit integer
- Compressed using FLAC
For more details about the format of the submission, please refer to the submission webpage.
The responsibility for the final remixed signal level is yours. It’s worth bearing in mind that should your signals overall seem too loud to be comfortable to a participant, they may well turn down the volume themselves. Also, there may be clipping in the evaluation block in some tasks if the processed signals are too large.
1.2 Evaluation Stage
You are not allowed to change the evaluation script provided in the baseline. Your output signals with be scored using this script.
The evaluation stage is a common stage for all submissions. As shown in Figure [1], the evaluation takes the reference stem signals, i.e., the eight reference stems, and the eight processed stems and computes the eight HAAQI scores.
To learn more about HAAQI, please refer to our Learning Resources and to our Python HAAQI implementation.
The output of the evaluation stage is a CSV file with all the HAAQI scores.
2. Software
All the necessary software to run the recipes and make your own submission is available on our Clarity-Cadenza GitHub repository.
The official code for the first challenge was released in version v0.3.4.
To avoid any conflict, we highly recommend for you to work using version v0.3.4 and
not with the code from the main branch. To install this version:
-
Download the files of the release v0.3.4 from: https://github.com/claritychallenge/clarity/releases/tag/v0.3.4
-
Clone the repository and checkout version v0.3.4
git clone https://github.com/claritychallenge/clarity.git
git checkout tags/v0.3.4
- Install pyclarity from PyPI as:
pip install pyclarity==0.3.4
3. Baselines
In the Clarity/Cadenza GitHub repository, we provide two baselines. Both baseline systems work in a similar way. Using a music source separation model, the systems decompose the music into the target eight stems. Both models were trained exclusively on MUSDB18-HQ training set and no extra data was used for augmentation.
Demucs: This baseline system uses theHybrid Demucsmodel. This is a time-domain-based model.Open-UnMix: This baseline system uses theumxhqmodel from Open-UnMix. This is a spectrogram-based model.
Please, visit the baseline on the GitHub webpage and Baseline links to read more about the baselines and learn how to run them.