The 1st Cadenza Challenge
The CAD1 challenge concluded in July 2023.
All signals and corresponding HAAQI scores submitted by participants are anonymously and openly accessible on Zenodo at https://zenodo.org/records/13271525
If you are interested in exploring this challenge further or using the submission signals, please cite the following paper:
Roa-Dabike, G., Akeroyd, M. A., Bannister, S., Barker, J. P., Cox, T. J., Fazenda, B., Firth, J., Graetzer, S., Greasley, A., Vos, R. R., & Whitmer, W. M. (2025). The First Cadenza Challenges: Using Machine Learning Competitions to Improve Music for Listeners With a Hearing Loss. IEEE Open Journal of Signal Processing, 6, 722–734. https://ieeexplore.ieee.org/document/11030066
Bannister, S., Firth, J., Roa-Dabike, G., Vos, R., Whitmer, W., Greasley, A. E., Graetzer, S., Fazenda, B., Cox, T., Barker, J., & Akeroyd, M. A. (2026). The First Cadenza Challenge: Perceptual Evaluation of Machine Learning Systems to Improve Audio Quality of Popular Music for Those with Hearing Loss. Trends in Hearing, 30, 23312165251408761. https://doi.org/10.1177/23312165251408761
The Cadenza Challenges are about improving the perceived audio quality of recorded music for people with a hearing loss.
Overview
What do we mean by audio quality? Imagine listening to the same music track in two different ways. First listening via a low quality mp3 played on a cheap cell phone, and then via a high quality wav heard over studio-grade loudspeaker monitors. The underlying music is the same in both cases, but the audio quality is very different - this is what we are interested in.
The tasks are based on two common listening scenarios:
- Task 1: headphones.
- Task 2: in the car.
You can enter one or both tasks.
Task 1: Headphones
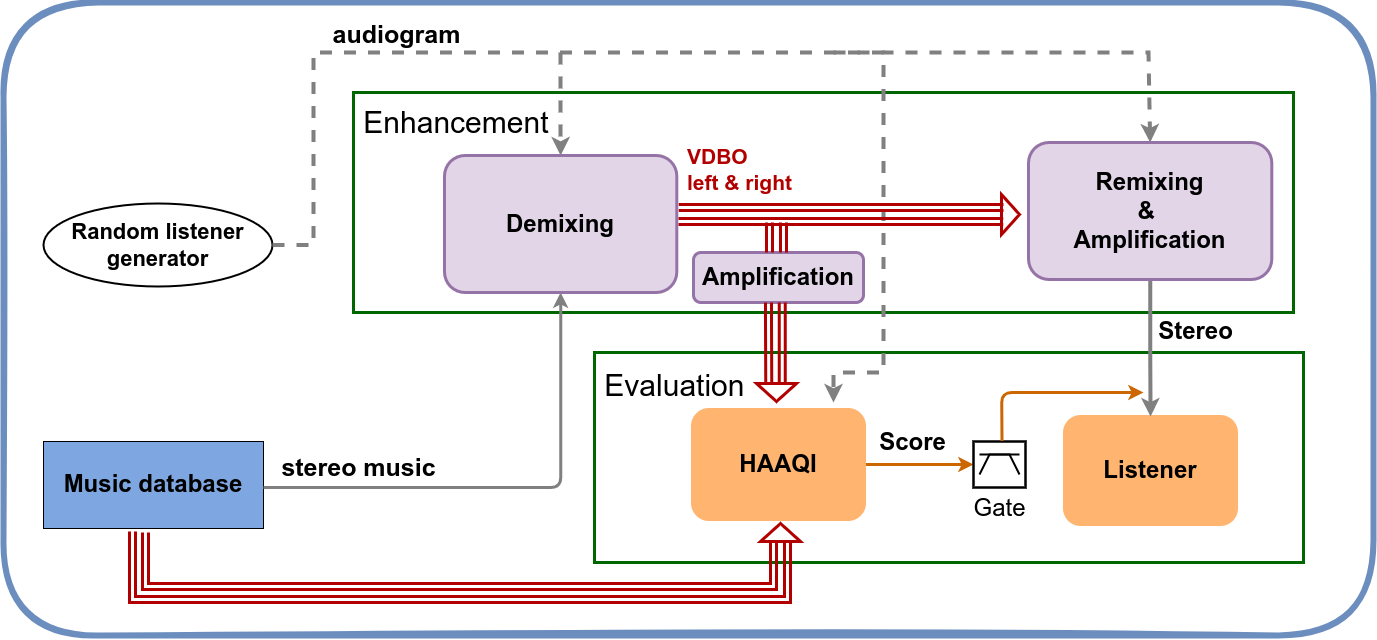
Someone with a hearing loss is listening via headphones, not using their hearing aids. As Figure 1 shows, the machine learning challenge here is to first demix stereo tracks into a VDBO (vocal, drums, bass and other) representation. This then allows a personalised remixing for the listener that has better audio quality. For example, for some music you might amplify the vocals to improve the audibility of the lyrics.
To evaluate the quality of the demixing, the objective measure HAAQI (Hearing aid audio quality index) is used. The evaluation of the remixed version will be via our listening panel.
The block that can be changed by you is labelled Enhancement in Figure 1.
While the main focus is on demixing/remixing, we'll accept entries using alternative signal processing approaches that can improve music for people with a hearing loss. Your entry would replace the whole box labelled enhancement.
Task 2: Car
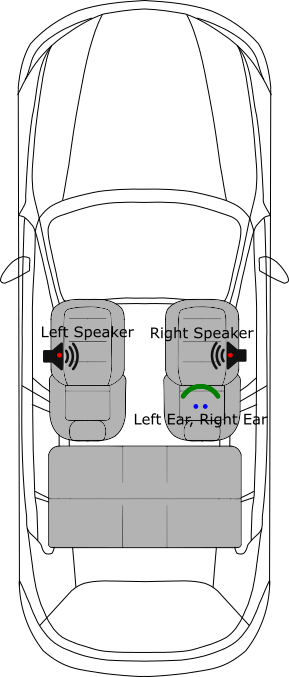
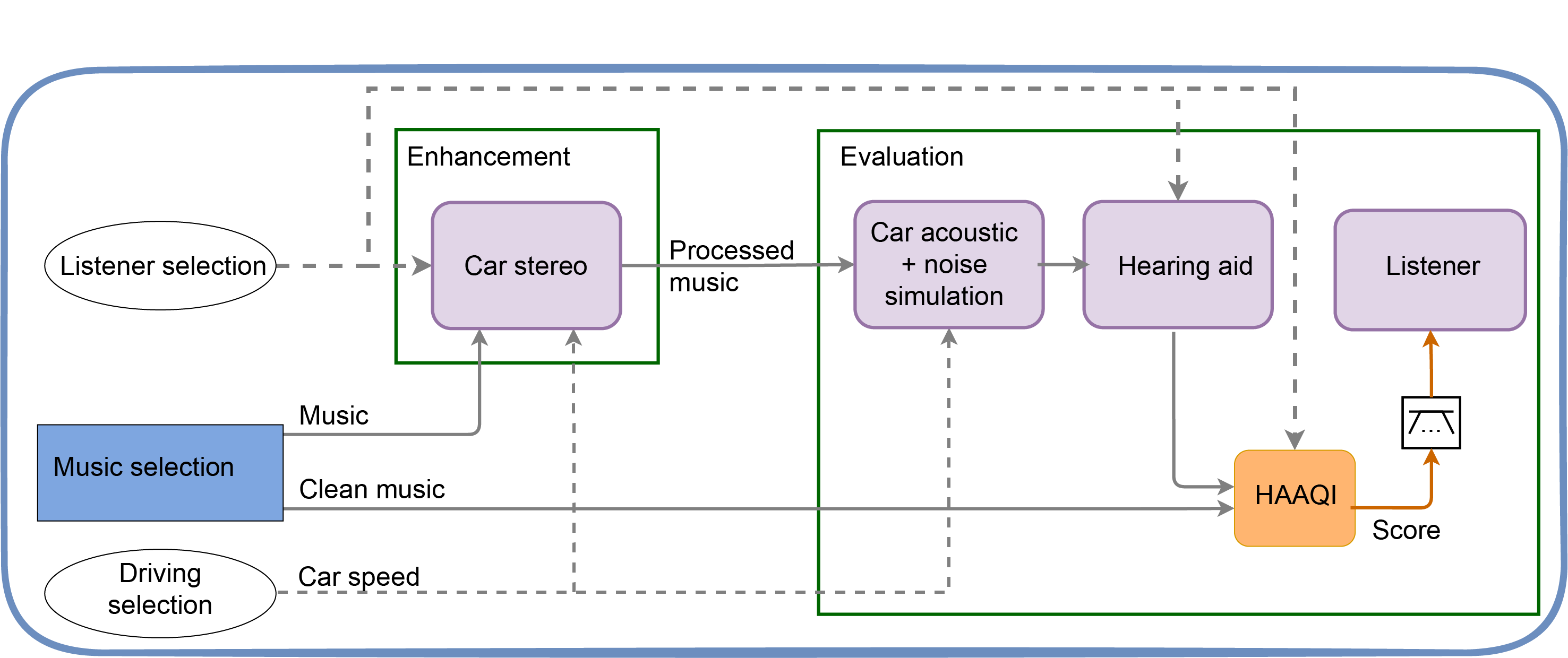
The listener is wearing their hearing aids, sitting in a car and listening to recorded music played over the car stereo (see Figure 2). Your task is to process the music played from the stereo to improve the audio quality allowing for the presence of the car noise. You have access to the car speed, which gives an estimation of the power spectrum of the noise but not the noise signal itself, so this is not a noise cancellation task. The block that can be changed is labelled Enhancement.
Watch the UKAN+ Webinar: Machine Learning Challenges to Improve Hearing Devices: Clarity & Cadenza Projects
For more details on the Clarity and Cadenza projects, please see this recording of the webinar given by Trevor Cox, Alinka Greasley, and Rebecca Vos on the topic: