The ICASSP 2024 Cadenza Grand Challenge
The ICASSP 2024 Grand Challenge concluded in January 2024.
All signals and corresponding HAAQI scores submitted by participants are anonymously and openly accessible on Zenodo at https://zenodo.org/records/13285031
If you are interested in exploring this challenge further or using the submission signals, please cite the following paper:
G. Roa Dabike, M. A. Akeroyd, S. Bannister, J. P. Barker, T. J. Cox, B. Fazenda, J. Firth, S. Graetzer, A. Greasley, R. R. Vos and W. M. Whitmer, "The First Cadenza Challenges: Using Machine Learning Competitions to Improve Music for Listeners With a Hearing Loss," in IEEE Open Journal of Signal Processing, under review.
Overview
There is a global challenge of an ageing population. According to The World Health Organization (WHO), over 1.5 billion people worldwide have hearing loss. and is projected to increase to 1 in 10 people having disabling hearing loss by 2050. Hearing loss causes problems when listening to music. It can make picking out lyrics more difficult, with music becoming duller as high frequencies disappear. This reduces the enjoyment of music and can lead to disengagement from listening and music-making, reducing the health and well-being effects people otherwise get from music. We want to get more of the ICASSP community to consider diverse hearing and so allow those with a hearing loss to benefit from the latest signal processing advances.
In this challenge, someone with a hearing loss is listening to music via their hearing aids. The challenge is to develop a signal processing system that allows a personalised rebalancing of the music to improve the listening experience, for example by amplifying the vocals relative to the sound of the band. One approach would be to a demix the music and then apply gains to the separated tracks to change the balance when the music is downmixed to stereo.
What makes the demix different to previous demix challenges?
The left and right signals you are working with are those picked up by a microphone at each ear when the person is listening to a pair of stereo loudspeakers. This means the signals at the ear that you have for demix is a combination of both the right and left stereo signals because of cross-talk (see Figure 1). This cross-talk will be strongest at low frequency when the wavelength is largest. This means that the spatial distribution of an instrument will be different in the microphone signals at the ear compared to the original left-right music signals. Stereo demix algorithms will need to be revised to allow for this frequency-dependent change. We will model the cross-talk using HRTFs (Head Related Transfer Functions), assuming the music comes from a pair of stereo loudspeakers in a dead room.
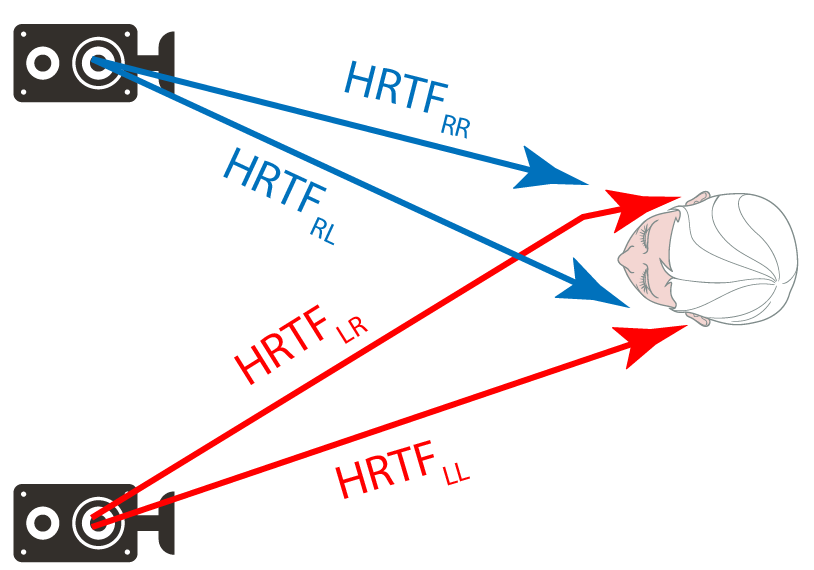
Although in the long term demixing on hearing aids would need to be causal and low latency, for ICASSP 2024 we are allowing causal and non-causal approaches. If you produce a low latency solution that will be great and very novel. There are increasing number of DNN approaches for causal signal processing from other areas such as speech that could be adapted for this.
Do I have to demix and then downmix to stereo?
Our baseline does demixing, but you don't have to. You could create an end-to-end system without an explicit demixing stage if you want.
Do I need to know about hearing loss and hearing aids?
Not really. We provide code for a standard amplification that is done by simple hearing aids. The challenge is mostly about rebalancing the music. We use a metric developed for hearing aids, but you could use another quality metric like Signal to Distortion Ratio (SDR) to develop your systems if you prefer. If you want to learn more about hearing loss and aids, however, there is lots of information in our learning resources.
The task
Figure 2 shows a simplified schematic of the baseline system:
- A scene generator (blue box) creates the scene characteristics:
- Music signal at the hearing aids' microphones.
- The required gains for the output signal for the vocals, drums, bass and other (VDBO).
- The reference rebalanced signal for scoring.
- The music enhancement stage (pink box) takes the music at the microphones as inputs and attempts to generate the rebalanced output:
- It estimates the VDBO components from the mixture.
- Then, it remixes the signal using the gains.
- Lastly, it applies listener-specific amplification following a standard hearing aid fitting.
- Listener characteristics (green oval) are audiograms and are supplied to both the enhancement and evaluation.
- The enhancement outputs are evaluated for audio quality via the Hearing-Aid Audio Quality Index (HAAQI) [1] (orange box). Note, HAAQI is an intrusive measure that requires a reference signal.
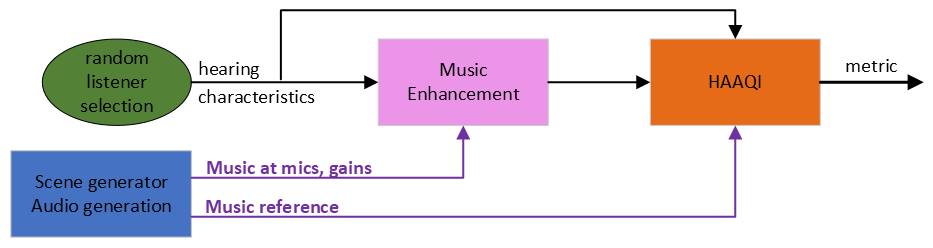
Your challenge is to improve what happens in the pink music enhancement box. The rest of the baseline is fixed and should not be changed.
We are interested in systems that are either: (i) causal and low latency for live music, and (ii) non-causal for recorded music.
What is being provided
You will have access to:
- Full length songs from MUSDB18-HQ dataset.
- HRTFs to model the propagation of sound from the loudspeakers to the hearing aid microphones.
- Scripts to pre-process the music and construct the music signals at the hearing aid microphones with HRTF applied.
- Music data for augmentation, if needed.
- Listeners characteristics (audiograms) - see Listener Data
- Target gains for the VDBO stems used to mix the target stereo
Please refer to data page and the baseline readme in GitHub for details. To download the datasets, please visit download data and software
The systems' output
Stereo downmixed signals
- Sample rate: 32,000 Hz
- Precision: 16-bit integer
- Compression: FLAC
For more details about the format of the submission, please refer to the submission webpage.
:::caution Note The responsibility for the final remixed signal level is yours. It’s worth bearing in mind there may be clipping in the evaluation block in some tasks if the processed signals are too large. :::
Evaluation Stage
You are not allowed to change the evaluation script provided in the baseline. Your output signals with be scored using this script.
The evaluation stage computes HAAQI scores for the remixed stereo - see Python HAAQI implementation.
The output of the evaluation stage is a CSV file with all the HAAQI scores.
Cite as
@misc{roa2023cadenza,
title={The Cadenza ICASSP 2024 Grand Challenge},
author={Gerardo Roa Dabike and Michael A. Akeroyd and Scott Bannister and Jon Barker and
Trevor J. Cox and Bruno Fazenda and Jennifer Firth and Simone Graetzer and
Alinka Greasley and Rebecca Vos and William Whitmer},
year={2023},
eprint={2310.03480},
archivePrefix={arXiv},
primaryClass={eess.AS},
note={to be submitted in ICASSP 2024}
}
References
[1] Kates, J.M. and Arehart, K.H., 2016. The Hearing-Aid Audio Quality Index (HAAQI), in IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 24, no. 2, pp. 354-365, doi: 10.1109/TASLP.2015.2507858.