Baseline System
Two baselines have been created. One is Intrusive because it uses the ground truth text and the other is Non-intrusive. These might be useful starting points for your algorithm, or you can do something completely different.
Non-intrusive
The non-instrusive baseline is based on short term objective intelligibility (STOI) [1]. STOI is an metric that compares two signals.
- A processed signal (Audio 1).
- A reference signal (The vocals in Audio 2).
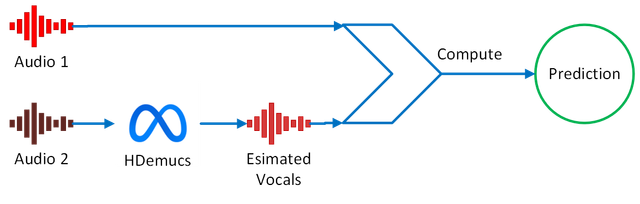
In the baseline, the reference signal corresponds to the vocals estimated from the original music i.e. the unprocessed track (Audio 2). The vocals are extracted using musical source separation (HDemucs [2]) on the signal before any hearing loss simulation.
Note, STOI is normally seen as being intrusive, but the way we have formed the reference makes it non-intrusive. Also, we have not adapted the method for lyrics, but Sharma and Wang have [3].
Intrusive
This baseline is based on ASR transcription using Whisper [4]. In this case, we use Whisper model base.en and temperature=0.0 to transcribe Audio 1.
Next, using the ground truth transcriptions, we compute the intelligibility (correctness) score, which is the fraction of words correctly transcribed to the total number of words in the ground truth.
Before computing the score, the ground truth and Whisper hypothesis were text normalised, e.g. numbers transcribed to written format and contractions expanded.
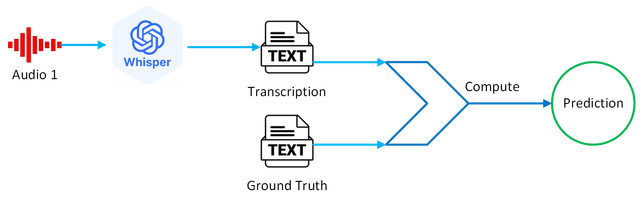
Note, ASR methods for speech intelligibility prediction have become popular in recent years, but most systems don't use the whole ASR to get the text, instead they map from a latent representation in the ASR to the target intelligibility. See entrants to the Clarity Challenge CPC3 for example. If you take that approach, the method becomes non-intrusive.
Logisitic mapping for both baselines
Raw predictions from the above algorithms lie between 0 and 1. These are then passed through a fitted logistic function to improve the mapping to the intelligibility scores (correctness) measured in the listening tests. For each baseline, this is done by optimising the parameters of the logistic function to minimize the RMSE between the predicted and measured intelligibility scores for the training set. The output of the logistic function is the final intelligibility prediction.
Introduction video to baselines
How to use the baseline
The baseline system is included in the pyclarity Python package (version pyclarity >= 0.8.0), which is available on GitHub.
The relevant scripts are located in the recipes/cad_icassp_2026/baseline directory. To use the baseline system:
- Download the Code: Clone or download the repository from GitHub.
- Follow the Instructions: Refer to the README file in the
recipes/cad_icassp_2026/baselinedirectory for detailed steps to run the baseline on the Cadenza ICASSP 2026 dataset.
Baseline Performance
The baseline systems achieve the following performance on the validation set:
| System | RMSE | NCC |
|---|---|---|
| STOI | 36.07 | 0.141 |
| Whisper | 29.20 | 0.598 |
References
[1] C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, An algorithm for intelligibility prediction of time–frequency weighted noisy speech, in IEEE Transactions on Audio, Speech, and Language Processing.
[2] Alexandre Defossez, Hybrid spectrogram and wave-form source separation in Proceedings of the ISMIR 2021 Workshop on Music Source Separation, 2021.
[3] Sharma, B. and Wang, Y., 2019. Automatic evaluation of song intelligibility using singing adapted STOI and vocal-specific features. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 28, pp.319-331.
[4] Radford, A., Kim, J. W., Xu, T., Brockman, G., McLeavey, C., & Sutskever, I. Robust speech recognition via large-scale weak supervision, in International conference on machine learning.