Dataset Overview
The training and validation data are provided at challenge launch. The evaluation data is provided closer to the submission deadline in November.
Download
The data is available on Zenodo.
Overview
The Cadenza Lyrics Intelligibility Prediction (CLIP) dataset consists of thousands of audio extracts of unfamiliar Western popular music, each paired with (i) lyric intelligibility scores from listening tests, and (ii) ground truth transcriptions. For each scene we provide:
- The stereo audio that our listeners heard during the intelligibility tests. This audio may have no, mild or moderate hearing loss simulated.
- The audio without hearing loss simulation (in cases where audio (1) has no hearing loss simulation, audio(1)=audio(2)).
- The hearing impairment severity applied to the audio (1).
- The ground-truth text of the lyrics.
- The transcription given by our listeners during the intelligibility tests and the intelligibility score.
See the rules for which of these can be used for training, validation and evaluation.
Why provide Audio (2)
The scenario we're simulating is someone listening to music, so audio (2) might be the signal fed to a pair of headphones. We're interested in diverse hearing and many people with hearing loss don't use hearing aids. Therefore in the listening test we added the effects of hearing loss to some of the audio (people doing our listening tests were young and had no hearing loss). Consequently, audio (1) is what people heard in the listening tests, but audio (2) is also available in our scenario.
In our baseline, we use Audio (2) to estimate the vocals without hearing loss simulation using music source separation. This is then used as a reference signal for an intelligibility metric.
Data exploration
This video explores the dataset and highlights some interesting aspects to research.
Construction of the CLIP1 Dataset
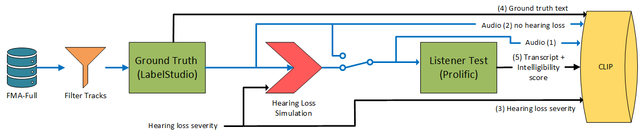
Figure 1. Schematic of data generated and process. Black lines indicate metadata and blue audio.
The audio in CLIP1 is based on the FMA dataset, which contains thousands of songs from various artists, genres and styles. Below the process to select audio excerpts; generate the ground truth transcriptions; and listener intelligibility scores is given.
Selecting the tracks from FMA
We began with the FMA-full, which includes all complete (untrimmed) songs. Then we:
- Filtered out any tracks whose license did not allow derivative works.
- Excluded songs labelled as Classical, Instrumental, Experimental, or International to get just English songs.
- Removed tracks without vocals. This was done using the HTDemucs audio source separation model [2] combined with the Silero VAD voice activity detector and RMS analysis.
- We then selected one chorus or verse per song. This was done after segmenting the track into choruses and verses using the All-in-one model [3].
This process resulted in just over 17,000 segments.
Generating ground truth lyric transcriptions
We used a structured annotation process supplemented with published lyrics on sites such as bandcamp and genius to clarify ambiguous cases where those were available.
The lyric transcription was done by native English-speaking PhD students from the Universities of Salford and Sheffield. Using the academic version of Label Studio, each annotator was assigned 500 random segments (choruses and verses) with no overlap between assignments. For each segment, three versions were presented to help the annotators: the original audio; the vocals extracted from the audio using musical source separation; and the audio with low-frequency bass removed. Annotators were allowed to listen to the tracks as many times as needed. Annotators were asked to flag obscene lyrics so they could be removed.
The resulting phrases were then post-processed to ensure data consistency and quality. We removed any repeated phrases from the same song; ones were a word was repeated more than twice; and retained only those containing between five and ten words. Audio boundaries were carefully adjusted to just include the ground truth words. This post-processing step resulted in a final set of 3,700 audio excerpts with ground truth transcriptions.
Note, in the ground truth, there are a small number of phrases containing highly unintelligible words where the annotator was unable to pick up the word. These words were marked as "?". We kept this data because they represent very unintelligible phrases that occur within sung language.
Listening tests to get intelligibility scores
We first divided the 3,700 audio excerpts into training, validation, and evaluation sets with an 80/10/10 split, ensuring no artist overlap between sets. Each excerpt was then processed using a hearing loss simulation for mild and moderate hearing loss. For the simulation of hearing loss, an audiogram with the appropriate hearing loss severity was chosen at random. This produced three versions of every excerpt.
Using Prolific, we recruited many native English speakers who were young adults with self-declared normal hearing. Each excerpt was presented twice, with the first serving to help listeners adapt to genre and vocal style. Listeners were asked to type what they heard.
Intelligibility scores were computed as the ratio of correctly transcribed words to the total number of words in the ground-truth text.
Ground truth and listener transcriptions were text normalised before computing the intelligibility scores as follows. We started by expanding contractions (e.g. I'm to I am). Next, we corrected any misspellings (e.g. remeber to remember) For the responses, we also looked for alternative transcriptions of homophones (e.g. your and you're). All alternative transcriptions were then transcribed using the BEEP pronunciation dictionary. This accounted for when transcribers used a different transcription of a homophone. This process resulted in one ground truth and several normalised transcriptions per extract. The final score corresponds to the maximum score across alternatives.
Examples of text normalisation
| Original Phrase | Alternative Phrase |
|---|---|
| i'm thinking about you now | i am thinking about you now |
| when were lost we know where to find it | when we are lost we know where to find it |
| were gonna tell you our names so you remember | we are going to tell you our names so you remember |
References
- Defferrard, Michaël, Kirell Benzi, Pierre Vandergheynst, and Xavier Bresson., 2017, FMA: A DATASET FOR MUSIC ANALYSIS, International Society for Music Information Retrieval.
- S. Rouard, F. Massa and A. Défossez, 2023, Hybrid Transformers for Music Source Separation ICASSP.
- T. Kim and J. Nam, 2023, All-in-One Metrical and Functional Structure Analysis with Neighborhood Attentions on Demixed Audio WASPAA.